New partnership gives Telarus advisors access to Summit’s cloud, data center, disaster recovery, and cybersecurity solutions
Alpharetta, Ga. Sept. 11, 2025 – Summit, an IT infrastructure provider delivering cloud, data center, disaster recovery, and cybersecurity solutions, today announced it has joined the Telarus supplier network. As a member of the Telarus Partners community, Summit will work with Telarus technology advisors nationwide to design, deliver, and support secure IT infrastructure.
For more than two decades, Telarus has empowered technology advisors to source, specify, deploy, and support the right solutions for their customers through a trusted community of proven supplier partners. As a new addition to the Telarus supplier network, Summit will work with channel partners to design and support tailored IT infrastructure that meets today’s performance, compliance, and scalability demands.
“Summit delivers enterprise-grade infrastructure supported by white-glove service and deep technical expertise,” said David Albanese, Director of Partner Operations at Summit. “By equipping advisors to deliver reliable, secure solutions for complex IT environments, we’ll build lasting partnerships and further strengthen the Telarus supplier network.”
As an official Telarus supplier, Summit will provide:
- Application Hosting: Scalable, secure platforms for running critical applications in the cloud.
- Data Center Services: Reliable colocation, dedicated infrastructure, and high-speed connectivity, supported by 24/7 Remote Hands for on-site technical support.
- Enterprise Cloud Services: Scalable private and multi-tenant cloud infrastructure, with flexible resources and enterprise-grade security.
- Disaster Recovery Services: Rapid system and data restoration with DRaaS and backup solutions that minimize downtime and ensure business continuity.
“Summit’s solutions and expansive data center presence perfectly align with Telarus’ vision of empowering technology advisors through world-class technology and strategic collaboration. This partnership expands our geographic reach and deepens the range of infrastructure and cloud services our technology advisors can offer,” said Koby Phillips, VP of Cloud Practice at Telarus. Together, we’re creating new pathways for innovation, efficiency, and long-term value for our technology advisors and their customers.”
Earlier this month, Summit representatives attended the 2025 Telarus Partner Summit, which featured 170 exhibitors and 47 sessions from over 100 supplier and Telarus leaders. The event also raised $36,000 for Team Rubicon, an organization that specializes in global disaster response and supported recovery efforts after the recent Southern California wildfires.
About Telarus
Telarus is a leading global technology services distributor with a singular focus on accelerating partner success. For over 20 years, Telarus has provided comprehensive services, solutions, and tools to support our partner community as they pursue their business objectives. To learn more, visit telarus.com.
About Summit
Summit is an IT infrastructure and application hosting provider delivering cloud, data center, disaster recovery, and cybersecurity solutions to organizations worldwide. From hybrid cloud deployments and secure colocation to managed backup and recovery services, Summit helps businesses operate with confidence, eliminate IT uncertainty, and scale on demand. For more information, visit summithq.com.
Let me guess: you’re sick of unpredictable and / or sky-high public cloud bills. (There’s no way cloud hosting should cost that much!)
Or else you’re tired of being beholden to a single provider for all your functionality.
Or maybe you’re at an inflection point in your growth: the cloud made sense five years ago but it doesn’t today.
And now you’re starting to hear rumblings from other people in your industry. You’re not alone. More and more of your peers are repatriating from the public cloud. It’s time. You want out.
Hang on.
I totally understand the FOMO, but rushing this move—and even rushing the decision of whether to leave the public cloud—can lead to disaster.
Instead, try this more methodical approach to cloud repatriation: first take the time to determine the best course of action for your organization, then make any changes incrementally.
Here’s how we approach these situations when they arise with our clients.
Start with the Problem, Not a Solution
Repatriation is a solution, but it may not be the right one for the nature of your cloud problems.
If you’re dealing with high bills, for example, maybe a different configuration or storage setup could deliver the cost savings you want. Ditto if you’re looking to boost performance. Maybe you could avoid the time and expense of repatriation entirely by allocating a fixed number of worker hours per week to infrastructure management. And so on.
Because while cloud repatriation is having a bit of a moment right now, it’s not one-size-fits-all. The first phase in any cloud repatriation project shouldn’t have anything to do with repatriation. Instead, it should involve inventorying all your workloads, architectures, dependencies, performance patterns, and costs and considering them within the larger business context.
In other words: first, you need a picture of where you are today.
Then, you can move to phase 2, where you score workloads using a workload typing matrix (critical, easy win, complex refit, etc.). Once you’ve done this work, you’re in a good place to determine whether repatriation makes sense to solve the problems you’re currently facing.
Think of it this way: if you start getting utility bills that are much higher than you expected, your first solution wouldn’t be to move to a new house. It would be to see what’s going on with your appliances: running toilet? Gas leak? Fridge on the fritz? Moving changes more than your utility bills; it changes your school district, your commute, your neighborhood amenities, etc.
Similarly, the problems you’re experiencing in the public cloud may or may not be best solved by repatriating. Doing the upfront assessment work is essential to the long-term viability of the business.
Related: Winning with Hybrid: How 5 Companies Optimized Performance with Hybrid Cloud Infrastructure
Design and Pilot to Avoid Downtime
Assuming you determine that repatriation makes sense, you’ll want to design a fit-for-purpose target architecture based on workload needs. That’s phase 3.
But it’s really important to avoid a “big bang” transition once you’ve got your destination architecture laid out. Big bangs introduce risk. They lead to unplanned downtime.
Instead, take an iterative approach. Run pilots of your new workload configurations. This lets you validate your models faster, learn what won’t work, and adapt. It lets you discover where your assumptions were wrong and identify performance bottlenecks before they’re scaled across your entire organization.
Above all, an iterative approach helps you avoid operational downtime.
Again, think of the house metaphor: if you’re going to all the trouble to move to a new location, it doesn’t make sense to solve just one problem (like cost of utilities). Why not also move to a better school district? A place with a nicer neighborhood pool? Better biking trails nearby? Better access to transit or nightlife or whatever else you value?
Cloud repatriation isn’t just an infrastructure move. It’s an opportunity to lay the groundwork for transformation. It’s rare to have this kind of opportunity in the life of a business, which is why it’s so important to make the transition in a considered, strategic way.
Prioritize Workloads based on Migration Complexity and Business Criticality
When you execute cloud repatriation incrementally, you can optimize in real time. What you learn in week one makes you more efficient in week two and beyond. This helps you stay on track, both budget- and time-wise, for the full repatriation.
So where do you start? We’ve found it’s helpful to prioritize workloads on two axes: migration effort / complexity and business importance (see diagram).
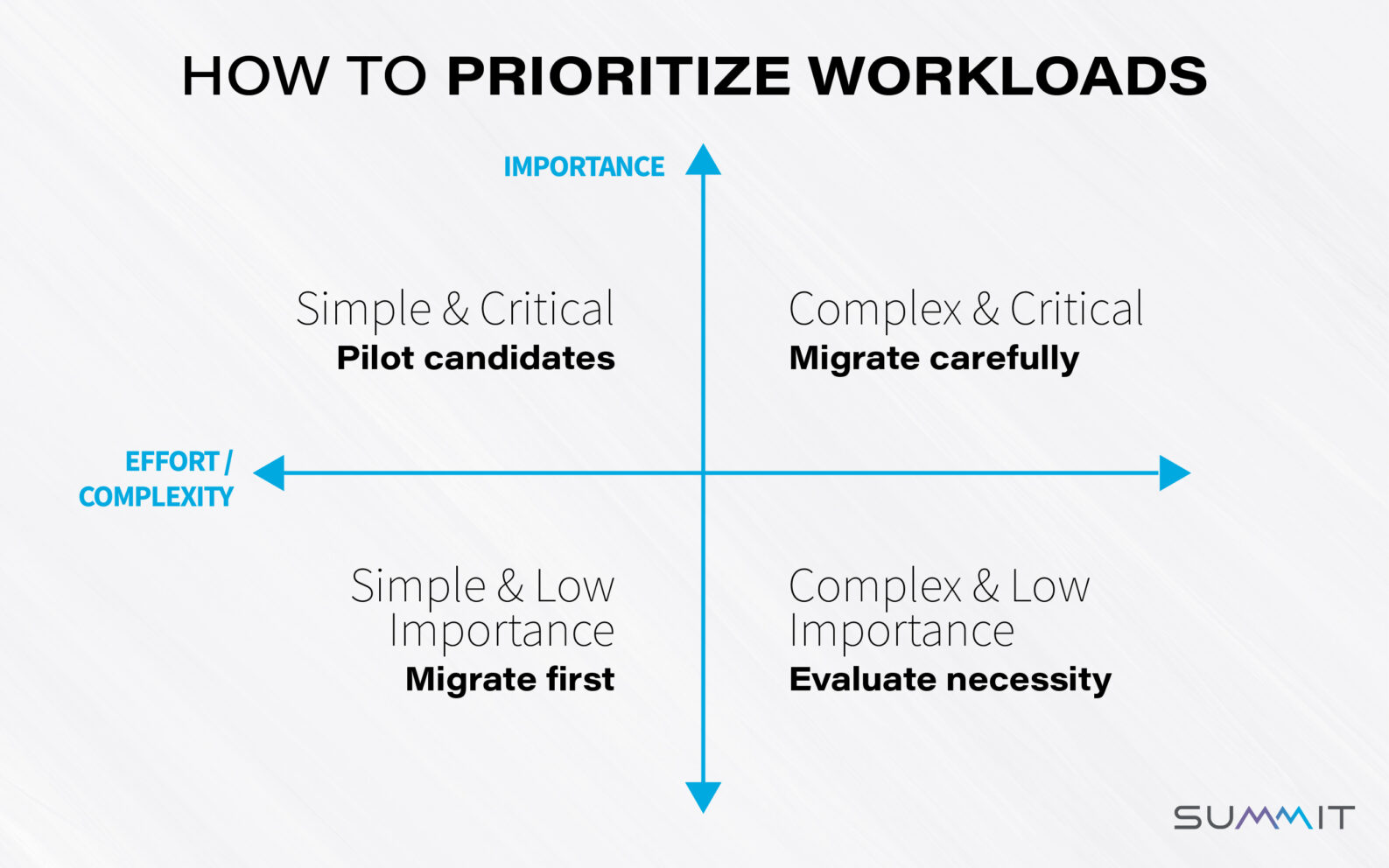
Workloads that fall in the bottom-left quadrant (simple and low importance) are good to migrate first. You’ll learn a couple things and you can get comfortable with the work of migration on these low-risk workloads.
Then consider creating pilots for those in the top left (simple but critical). Things here ~should~ go well, but if they don’t, the business suffers. A pilot lets you do a test run, then adapt as needed.
Workloads in the top right are both critical and complex. These require the most care to migrate.
Finally, workloads in the bottom-right quadrant, which are both complex and of low importance, should be assessed for necessity. That is: do you need to migrate them at all? Or can you sunset them?
This prioritization framework helps keep you focused on the big-picture business needs even as you dig into deep technical work.
Repatriation Is an Opportunity to Build the Groundwork of Transformation
Today, many organizations are considering cloud repatriation because the costs of operating in the public cloud have gotten unsustainable. But repatriation can achieve so much more than cost reduction.
If your organization is considering public cloud alternatives, keep the big picture in mind: high cloud bills are a symptom. The best solution depends on the underlying cause.
So before you rush into repatriating all your workloads, take the time to understand where you are today, identify where you’d like to be from a business perspective, and then create a plan for getting there incrementally—regardless of whether you decide to leave the public cloud.
When you take this methodical, gradual approach, you’ll save resources and end up with infrastructure that’s better suited to your long-term goals.
Like spam emails and pop-up ads, distributed denial of service (DDoS) attacks have been around since the arrival of the internet. Unlike those annoyances, however, DDoS attacks can be a genuine threat to your business – and they’ve been on something of a tear lately.
DDoS attacks, in fact, have been growing exponentially – both in rate and in size. In the first quarter of 2024, for example, HTTP DDoS attacks went up by 93 percent YoY, while the average attack size increased by more than 200 percent. And this escalation has only continued since then.
It seems, unfortunately, that we’re living in a golden age of DDoS. And while some companies and industries are more susceptible than others, odds are almost every business is going to fall victim to an attack at some point.
That’s why now is the time to talk with your managed services provider about how to mitigate the risk of a DDoS attack. These three questions are a good place to start.
1. Is DDoS a threat to our business readiness?
Unfortunately, that’s kind of the point of DDoS: DDoS attacks take your business offline. That’s why this is a great time to be proactive.
To review, the goal of a DDoS attack is to overwhelm server resources with huge numbers of requests to force an interruption of work. The result? Downtime.
No company wants its services to be down for any length of time. But not every DDoS attack hits the same. So start by assessing the threat landscape to your business, taking into account these key questions:
- Are we more susceptible to a DDoS attack than other businesses? (Hint: if you’re in an industry like financial services or academia, the answer is probably yes.)
- Is the downtime from an attack more likely to be a minor disruption for customers or a major outage that costs us far more in lost business? The average DDoS attack cost nearly half a million dollars in 2023. What would that mean to your balance sheet?
- In addition to any opportunity cost losses from that downtime, how much will it cost to recover from the attack itself? What about the cost of rebuilding trust with affected customers?
- How big is our risk for a DDoS attack that goes beyond mere disruption and veers into the more malicious territory of ransomware?
The answers will vary for different companies. But given the explosion in DDoS activity over the past several years – and the significant revenue at stake – it’s a good idea to have this conversation now (so you don’t have to panic later).
2. If we can’t stop DDoS attacks, how do we stay online?
The good news about DDoS attacks is that while you can’t prevent them, you can mitigate the risks.
And the good news is that advances in technology have increased the number of options for companies looking to protect themselves from DDoS attacks. For instance, instead of relying on old-fashioned protections like firewalls and router ACLs, many managed service providers (including Summit, ahem) now offer more modern options like scrubbing services.
A scrubbing service is essentially a filter. When a massive amount of traffic is detected, an alert is triggered to reroute that surge to a scrubber. The scrubber analyzes this load, removes the junk traffic meant to overwhelm the system, and sends the clean traffic back to the business. Or it may shut down the one IP address among many that’s absorbing all of the suspicious traffic.
In either of these scenarios, service may be degraded for a short period, but there’s no costly long-term outage. And that’s the goal of scrubbing – not to be perfect, but to keep things up and running instead of getting shut down completely.
Of course, threat actors have been keeping up with technology as well. Which means they’ve been able to launch more complex attacks – and stay several steps ahead of the protections meant to thwart them. That’s why the more pertinent question here for your managed services provider – how can you help protect us? – is one that needs to be revisited often.
3. Are we overpaying for DDoS protection (especially if it doesn’t always keep us online)?
If you’re satisfied with the protection options your managed services provider offers, this is the next question to ask (if you’re not, it may be time to look elsewhere). The discussion surrounding question 1 should help guide your answer here.
DDoS protection isn’t free, so you want to be sure you’re paying for a level of protection that makes the most sense given your risk exposure.
For example, if you’re a higher-profile business – say a bigger company or one in a more vulnerable industry – you may want to splurge for the highest level of protection available, regardless of the cost. After all, if you’ve determined that persistent DDoS attacks are probable, and that those attacks could result in significant losses, the cost of ever-present protection is likely worth the investment.
On the other hand, if you’re a smaller company that doesn’t expect frequent attacks, you might decide you’re fine with a lower, less expensive level of protection.
In either case, you’ll likely be choosing between two kinds of scrubbing models:
- An on-demand model, where you hold a sum of money in a DDoS reserve fund. If an attack happens, you can call your service provider for on-demand DDoS scrubbing and write them a check.
- A service model, where you pay for a DDoS scrubbing service that is set up and ready to go at all times. The provider monitors traffic and triggers action when necessary. One advantage of this model is the opportunity to basically dry run the scrubbing to give the system an idea of your company’s traffic patterns. This way, when an actual attack unfolds, everyone has a better idea of what that looks like.
The key to determining what level of protection makes sense goes back to doing a risk and budgetary assessment. If being down for 20 minutes is going to mean $100,000 in lost revenue, the cost of a dedicated scrubbing service that is online and ready to go at any time is probably money well spent.
Don’t Go Dark. Avoid the Costs of Downtime with DDoS Protection
DDoS attacks aren’t going away. If anything, they’re becoming more frequent and potentially more damaging. That’s why you need to understand what your threat level is and what steps you can take to protect yourself.
We understand the DDoS risk landscape. Get in touch to learn how we can help.
If you’re like 83 percent of CIOs right now, you’re planning to move some workloads away from the public cloud this year.
But there’s also a good chance you don’t have the in-house experience to run an on-prem data center or manage a hybrid cloud setup. That can make it hard to know where to start or what to expect.
Not to worry. In this piece, we’ll look at five examples of companies optimizing performance with hybrid cloud infrastructure. As you read, keep in mind: these are intentionally high level. In any real-world scenario, the best course of action requires asking a lot of questions to understand the unique situation of the business in question.
Example 1: An Overpriced Chatbot Leads to Cloud Repatriation
The situation: A SaaS company introduces an AI chatbot to help customers find support documents. The IT team decides to launch the chatbot with pay-as-you-go GPUs on the public cloud. After all, the chatbot is an experiment and they don’t want to commit too many resources if it’s a flop.
Initially, adoption is low. But then the front-end team updates the website so the CTA to use the chatbot is more prominent. More and more customers start using it, and the company’s cloud bill skyrockets. The CFO sends an angry email to the head of the chatbot team demanding answers.
The diagnosis: This is a classic example of one common driver of cloud repatriation: right tech then, wrong tech now.
The public cloud is an excellent place to experiment for precisely the reasons this team identified: low upfront costs make it inexpensive to run experiments.
But there’s another truism about the public cloud: once a workload reaches a steady state, it often makes more sense (financially and operationally) to move it out of the public cloud.
That’s known as cloud repatriation: moving some (or, rarely, all) of your workloads out of the public cloud and into a private cloud, an on-prem data center, or a colocated setting.
In this case, the IT team consulted with an experienced managed services provider to identify an on-premises hosting setup for the chatbot. The result: lower latency and lower, more predictable monthly costs.
The takeaway: If your public cloud bills are significantly higher than they used to be – especially if you’re using GPUs in the public cloud – that’s a sign to look into hybrid cloud solutions like cloud repatriation. A hybrid setup might let you achieve better performance for a similar investment – or maintain your performance for a smaller investment.
Example 2: A Nationwide Outage Leads to More Diversified (and Resilient) Infrastructure
The situation: A cloud architect for a healthcare company deploys resources across multiple availability zones within a single region of the East Coast for redundancy. The platform hums along great – until a few months later, when an unexpected outage brings down the entire system, affecting users nationwide.
The diagnosis: This is an example of what we call right tech, wrong execution.
Tech outages are a reality of life. In architecting solutions, you have to plan for these things, because they happen no matter who’s in charge. The responsibility of the person designing and building cloud architecture is to plan for the most likely scenarios and then deal with the impacts.
In this scenario, the cloud architect did plan for business continuity by deploying across multiple availability zones. But they didn’t think about what would happen in the event of a full-region outage. With what little we know about this scenario, it sounds like a case of the architect not knowing what they didn’t know.
This is why working with a more experienced partner can be so valuable to prevent business outages. They know to ask questions you might not even be thinking about. After an outage, they can help you reassess and regroup with the right questions:
- What caused the outage?
- How can you address that failure point in your design?
- How can you set yourself up for better availability and greater resiliency moving forward?
The takeaway: In this scenario, it’s not necessarily the technology that needs to change. Rather, this organization needs a better plan for potential outages and better mitigation resources.
Example 3: Ghost Instances Lead to Tapping a Managed Services Team
The situation: A global entertainment company hosts a worldwide livestream event on AWS. It was the obvious choice to help the company manage unpredictable spikes in traffic. But after the event ended and audiences dropped off, several instances were left running at full capacity for hours – and the company was still being charged.
The finance team was furious.
The diagnosis: This is another example of right tech, wrong execution. AWS was a solid decision for the point-in-time solution this company needed. But whether someone on the IT team missed key requirements or implemented requirements poorly, the result was expensive. Machines weren’t turned off and they weren’t using auto-scaling to make changes.
The takeaway: The public cloud is an excellent solution for many hosting needs. But it has to be managed properly. Without proper management, costs can quickly spiral, as this company saw.
The good news is that managing a public cloud instance is not something your organization has to do on its own. In fact, most organizations can’t afford to staff enough people with the right skill set to actively and continuously manage their public cloud use.
This is where a trusted partner can prove invaluable, helping ensure that your product or service functions as needed without incurring unexpected costs.
Example 4: Million-Dollar Downloads Leads to a Hybrid Storage Solution
The situation: A video production company stores terabytes of video footage in the public cloud. For a short-term project that requires global collaboration, they need to download large portions of that footage to their laptops for editing.
When they get their cloud bill, it’s 10x what they were expecting.
The diagnosis: This one depends. It might be a case of right tech then (when the use case was archival storage), wrong tech now (when the use case is downloading data to edit). Or maybe it’s wrong tech, right execution – meaning the exact technology ended up being too expensive, but the approach of using the simplest available method to host data made sense.
As I mentioned at the top, every situation is different. Making a “diagnosis” is impossible without knowing the details. Still, thinking about these situations in broad terms can help IT leaders understand the nature of the infrastructure problem they’re trying to solve – and therefore whether a hybrid setup makes sense as a solution.
For example, if the data downloading was a one-time, time-sensitive thing, then maybe the company doesn’t need to make any changes. It’s very possible that the expense would have been justified.
The takeaway: Know what questions to ask before you make a cloud infrastructure decision. There’s no one-size-fits-all solution, which means every decision depends on someone considering the specifics of your organization’s situation against the potential solutions available.
Example 5: Forgetting to Hit Delete Leads to Managed Services Support
The situation: A mid-sized SaaS company regularly spins up cloud instances for testing and development. But devs don’t always remember to shut down instances they’re finished with. The result: orphaned databases and other resources that are not being actively used but continue to accumulate costs month over month.
The finance team notices an increasing number of these that aren’t generating business value.
If this one sounds familiar, you’re not alone. Many companies that moved to the public cloud did so without thinking through how their operations would change once they got there.
When devs requested additional servers from an on-prem data center, they submitted a ticket and IT gave them a server. Maybe they followed the same protocol in the cloud, but nobody added a step for shutting down the instances when the work was complete.
The diagnosis: Right tech, wrong execution.
The takeaway: Maybe the most important thing to remember about using the public cloud is that it can do pretty much anything – but that doesn’t mean you should do everything there. In other words: just because you can doesn’t mean you should.
With the support of a managed services team, the SaaS company didn’t have to worry about creating or enforcing rules for spinning up and shutting down instances – or otherwise managing their public cloud usage. They could focus on fixing bugs, building new features, and otherwise helping the business excel.
When You’re Considering a Hybrid Cloud Setup, Follow This 4-Step Process

We’re in a dynamic, constantly evolving world. If it’s been multiple years since you last considered your cloud infrastructure, now is a great time to review it and determine whether a different combination of public cloud, private cloud, on-prem, and colocated hosting might serve you better.
To do that effectively, follow this four-step process:
- Ask whether you’re in the right place. Whether it’s a massive cloud bill, an unexpected outage, lagging performance, or murmurings you’re hearing about hybrid capabilities, follow your instinct to question your strategy if you’re all-in on the public cloud. Starting the conversation is the first step to ensuring your infrastructure is optimized for growth.
- Review workload placement. This is a great step to collaborate on with an experienced partner. The goal: assess your current utilization and identify your true infrastructure needs.
- Get the right plan. While 83 percent of CIOs are considering cloud migration this year, only nine percent expect to go fully on-prem. Consult with an experienced partner to understand the many options available and identify the one that best fits your business needs.
- Migrate successfully. This might involve timing data migration, refactoring applications, and much more. The goal: end up with a cloud infrastructure that delivers better performance and offers greater financial transparency – and, in many cases, lower bills.
If you’re ready to start that process today, get in touch. We’d love to help you understand whether your current situation makes you a good candidate for cloud repatriation.
An AI-powered company repatriated from AWS to a private cloud to boost capacity and performance while cutting costs.
Challenge
A cloud-native AI recruiting platform reached maturity and found that the costs of its AWS infrastructure were becoming unsustainable. Initially attracted by the scalability of the public cloud, the company no longer needed many of the features it was paying for. What’s more, scalability had become less of a concern: user demand and expectations were steady. Peak loads happened at predictable times. And because the company relied heavily on powerful graphics processing units (GPUs) to run its LLMs, it anticipated major cost increases as it continued to grow.
Solution
The company showed Summit its AWS bills and we knew right away that they could save money by repatriating to a private cloud. But before recommending the switch, we dove into its workloads, architectures, dependencies, performance patterns, and—most importantly—business context.
This analysis made it clear that the company could both save money and enjoy significant performance improvement by repatriating.
So we moved through the Summit Repatriation Framework (SRF) to ensure the process caused minimal business disruption, yielded fit-to-purpose solutions, and was de-risked at every stage.
Ultimately, the company repatriated to a private cloud operated by Summit for a monthly fee.
Results
- Cost savings: With Summit as its partner, the company spends 30% less on monthly cloud costs than it did with AWS.
- Increased capacity: When used to power a private cloud, the same budget paid to AWS delivered 50% more processing power than it did on the public cloud, meaning the company had plenty of room to grow without increasing spend.
- Human support: There’s no such thing as support from a hyperscaler like AWS. With Summit, the team can talk to a real engineer instead of an AI chatbot.
- Noticeable performance improvement: Swapping shared network storage in AWS for dedicated local storage from Summit led to a noticeable improvement on performance.
Conclusion
This company’s experience demonstrates how AI-powered companies that rely on GPUs to power LLMs can enjoy both cost savings and performance improvements by repatriating from the public cloud. This experience is particularly relevant to companies entering scale-up and those that have achieved a steady state. At that point, when workloads are stable and demand is predictable, the costs of the public cloud often start outweighing its benefits. Repatriating to a private cloud setup reduced the company’s operating costs and positioned it for growth.
However, it’s important to note that cloud repatriation should always be considered in the larger business context and, when it makes sense, executed with consideration for impact and future performance. The Summit Repatriation Framework takes those things into account to guide every business toward the hosting infrastructure that makes the most business sense.
When image editing and sharing app Picsart got a bill from Google Cloud Platform (GCP) three times higher than normal, they were shocked. Worse: the line item responsible for the pricing surge was described only as “data transfer.”
But the final straw was when GCP refused to answer Picsart’s calls unless they upgraded to an enterprise account. At the time, the app company was spending hundreds of thousands of dollars a month with the hyperscaler.
It’s an infuriating scenario, but one that’s becoming common for growing companies hosted entirely on the public cloud. In fact, 93 percent of senior-level IT professionals are now intentionally combining public and private cloud in their hosting setup.
Their top priority for the next three years? Building workloads in the private cloud.
If any of this resonates, you (like Picsart) are likely considering cloud repatriation as a way to bring greater predictability to your hosting costs and future-proof your most important workloads. In this piece, we’ll explain how bringing workloads off the public cloud with help from a managed services provider can help you do exactly that.
Better Performance, Predictable Costs
One thing Picsart liked about GCP was the flexibility. During 2020’s pandemic quarantine, the app saw a surge of usage that its hyperscale host handled elegantly. But as they introduced more AI and machine learning features, the cost of hosting in the public cloud kept climbing.
On-prem hosting didn’t seem like a viable alternative, however: GPUs are expensive and hard to get. They have a short shelf life. The Picsart team knew it wasn’t viable for them to invest so much time and money in managing an AI-capable data center.
When they started considering managed services partners to help them migrate from the public cloud to a hybrid setup, they looked for the following capabilities:
- Scalable architecture: The ability to spin up (and down) GPU nodes and storage quickly without compromising performance.
- Resilient infrastructure: Excellent power, cooling, and failover support so performance didn’t drop when demand spiked.
- Security baked in: This includes everything from multi-factor authentication to disaster recovery – key if you operate in a highly regulated industry or are handling sensitive data.
And then there were the cost considerations.
As industry analyst David Linthicum points out in a recent InfoWorld article, “public cloud providers are not incentivized to dramatically lower costs,” despite the falling costs of the hardware they use to provide their cloud services.
Why? Lowering costs could hurt shareholder returns, for one thing.
For another, hyperscalers’ business models are highly complex and they offer a variety of ancillary services that can benefit cloud customers.
One public cloud alternative Linthicum highlights is managed services providers. But MSPs aren’t just a more cost-effective option – they also deliver essential support the hyperscalers generally don’t.
Guidance, Support, Advice – When You Actually Need It
As Picsart learned the hard way, GCP and other hyperscalers require a huge financial commitment before they’ll offer expert guidance and human support.
MSPs are the opposite.
At Summit, for example, we offer live human support 24/7/365. After a while, you might even recognize the voice of the person who picks up the phone.
And this isn’t just something we offer when things go wrong.
From day one, we’ll work with you to develop a migration plan that makes sense for your organization and your growth goals.
This is huge for a lot of companies looking to repatriate workloads to the private cloud. As many as 30 percent of IT leaders cite a lack of internal skills as a barrier to private cloud adoption. In other words: they’re not making the move because they don’t have the know-how to make it work.
What’s more, 80 percent of in-house teams rely on professional service providers (like us) to handle their cloud-related needs.
That’s only natural given the way the industry has evolved. Most people entering IT in the last decade or so have only ever worked in a cloud-first world. Evolving to a hybrid posture will naturally require support from experts who have been working with private cloud, colocation, and other hosting setups all along.
One word of caution, however: as you choose the partner to guide your repatriation, make sure they’ve got a track record of success.
Warning: Don’t Be the Crash Test Dummy
This is especially true if you’re looking to repatriate AI workloads. Many MSPs say they can provide an AI-ready hosting environment—and it may look like that on paper.
But looks can be deceiving.
The truth is that AI is still relatively new—new enough that many providers haven’t actually put rubber to the road when it comes to their AI promises. The last thing you want is to be the crash test dummy strapped in on their first run.
That’s why it’s important to make sure you’re choosing a provider that’s already managed AI workloads. More specifically, you want a partner that has already deployed every major GPU type, understands how to navigate the pitfalls that come with AI scaling, and can handle the power, cooling, and storage demands these systems introduce.
That’s where Summit stands out. Our team has enough experience to support your AI ambitions at any stage. We’ll help you figure out your steady state workloads, choose the right home for your data (e.g., hybrid cloud), and help you optimize deployment.
As you’re researching partners, ask about past successes with work similar to yours.
For example, consider the AI recruiting platform Summit recently helped repatriate from AWS, where their costs were skyrocketing as they reached a steady state.
With the hybrid solution we devised for them, they enjoyed…
- 30% cost reduction from their AWS spend.
- 50% more processing power compared to their AWS setup.
- Ample room to grow without increasing spend.
- Support from human engineers rather than AI chatbots.
- Noticeable performance improvement, thanks to local storage (vs. shared network storage from AWS).
Future-Proof Your AI Hosting with a Managed Services Provider
The public cloud is a great place to experiment with AI workloads. It’s quick, low-commitment, and scalable as you figure out what works.
But once you enter a steady state, the public cloud gets expensive and difficult to manage. That’s only going to get more true as you scale up. If you’re looking for ways to optimize your cloud investment, ensure peak workload performance, or otherwise future-proof your most critical workloads, it’s time to consider what an MSP can offer.
We’d love to hear what’s keeping you up at night right now. If it’s related to your public cloud usage, there’s a good chance we can help you sleep better.
When a top manufacturer realized its complex infrastructure was doing more harm than good, it made a bold pivot: transition away from hyperscalers and leave hybrid for a private cloud fully managed by Summit — in lockstep with strategic advisor Intelication.

When Hybrid Cloud Started to Snap
With 26 production facilities and multibillion-dollar operations, this manufacturer was no stranger to complexity. But as workloads grew and data demands soared, cracks in their hybrid cloud environment became hard to ignore.
Hybrid cloud complaints included:
- Spiraling costs without clear explanations
- Little personalization or proactive support from AWS
- Internal teams that lacked the expertise to optimize or right-size infrastructure
The tipping point came when the client could no longer afford guesswork or vendor runarounds. This was beyond a lift-and-shift — they needed a partner to guide them through a strategic transformation.
Why Summit’s Managed Private Cloud (and Intelication’s Great Relationship) Won the Deal
This wasn’t just a technical migration — it was a trust-first relationship built over time. The client had already worked with Summit inside AWS, laying the foundation for deeper engagement. Then, face-to-face meetings in Illinois and Ashburn cemented mutual alignment.
Requirements for a managed private cloud migration:
- Tailored Support, Not Templates: Summit delivered white-glove service from design to deployment
- Transparent Pricing: No mystery billing, no surprises — just clarity and predictability
- Hands-On Expertise: Summit acted as a true extension of their IT team, not a black-box vendor
- Guided by Intelication: Stephanie Rubin and her team offered financial modeling, technical vetting, and steady client advocacy every step of the way
Full-Stack Cloud Infrastructure, Designed for Results
What started with AWS cost modeling evolved into a full-stack infrastructure transformation. The client now leverages nearly every layer of Summit’s platform — a true showcase of what intentional IT modernization looks like.
What Summit delivered in the transformation:
- Managed Private Cloud: High-performance infrastructure optimized for graphic-intensive workloads
- Hybrid Cloud Integration: Continued flexibility with AWS and Azure where it makes sense
- Disaster Recovery-as-a-Service (DRaaS): Regularly tested failover and true enterprise resiliency
- Advanced Monitoring & Backup: Always-on visibility with comprehensive data protection
- Remote Hands & Licensing: Full-spectrum support with none of the friction
The Intelication Factor
This success story wouldn’t have been possible without the deep, trusted relationship between the client and Intelication. Led by Stephanie Rubin, Intelication brought:
- Real-time financial and technical clarity
- Unbiased guidance to support confident decision-making
- Unwavering client advocacy to keep business needs front and center
As Summit’s Joshua Airman put it: “We positioned ourselves as the voice of truth, earning trust through transparency and technical integrity.”
Results of a Hybrid to Private Cloud Migration
This wasn’t just about cutting cloud costs — though that was part of it. The bigger story is about resilience, confidence, and long-term alignment.
The hybrid to private cloud transformation delivered:
- Operational Continuity: Production never slowed — even during migration
- Cost Savings: Real monetary returns after leaving AWS (metrics pending client disclosure)
- True Strategic Partnership: A long-term, $3M+ contract secured through 2030
- Enterprise-Grade Support: High-touch service that hyperscalers couldn’t match
What Comes After Infrastructure Transformation
Now stabilized and optimized, the client is looking ahead with Summit and Intelication to tackle:
- Application modernization
- Deeper hybrid cloud orchestration
- Ongoing infrastructure innovation
Ready to Move Beyond the Hype?
If cloud complexity is slowing your business down, Summit can help you modernize with confidence — one intentional step at a time.
Channel Fam: Want to Be the One Clients Trust?
Summit works with partners like Intelication to win long-term deals built on real value. From cost modeling to cloud migration, we help you bring strategic insight and infrastructure muscle to the table.
Let’s build your next big win: Partner with Summit.
In the early 2010s, the message was clear: ditch your on-prem data center and embrace the public cloud. For many leaders, public cloud promised a dramatic upgrade in speed, scalability, and ease.
But a lot has changed since then. The private data center has evolved. Its users enjoy many of of the same capabilities that public cloud offers – without much of the headache that frustrates many companies today. And with a managed services partner, hybrid infrastructures that include both the public cloud and private data centers are easier to manage than ever.
In this piece, I’ll explain why the data center you left isn’t the one you’d be returning to and how to know it might be time to migrate certain workloads.
Modern Data Centers Deliver the Best of the Public Cloud
It makes sense why many companies embraced the public cloud in its early days. On-prem data centers are a pain to set up and manage on an ongoing basis. Just provisioning a server can take weeks and requires deep internal expertise.
With public cloud, though, teams can provision infrastructure with a few clicks. They can automate deployment using scripts. And they can pay for compute based on usage, from the OpEx budget, instead of investing significant capital in setup and maintenance.
But for all its benefits, public cloud has introduced a new set of challenges, such as:
- Vendor lock-in
- Unpredictable performance
- High service fees
- Cloud sprawl (i.e., uncontrolled proliferation of an organization’s cloud services)
That’s why many organizations are reassessing their infrastructure mix. And they’re finding that modern data centers now mirror the best parts of what the public cloud has to offer.
Instead of locking companies into proprietary tools from public cloud vendors, however, today’s data centers take advantage of new third-party and open-source tools (like Terraform and OpenTofu), which offer Infrastructure-as-Code capability anywhere and to anyone. There are also digital tools available to support:
- Automated deployment: Thanks to robust IPMI and platforms like Tinkerbell and Canonical MAAS, provisioning bare metal is now API-driven
- Configuration management: Systems like Ansible, SaltStack, and Puppet let teams deploy quickly
Now, companies rethinking their use of public cloud infrastructure can enjoy new levels of performance and efficiency by embracing a hybrid model. What’s more, they can get creative in how they manage their resources – crucial in today’s uncertain economy.
For example, you can tailor a hybrid solution that meets your business priorities, balancing cost, performance, and management. You can decide what you need and want to manage without a barrage of micro-charges on your bill.

The bottom line? Early public cloud providers may have raised the bar for excellent infrastructure. But today’s data centers have more than caught up (and provide more choices).
5 Myths Keeping Companies from Embracing Hybrid Cloud Infrastructure
CIOs are paying close attention to data center advancements. In fact, 83 percent are planning to move some workloads away from the public cloud, and fewer than 10 percent are going fully on prem. The implication: many business leaders are quickly recognizing that hybrid is the way forward.
That said, there are still plenty of holdouts. In my experience, five common misconceptions make many leaders hesitant to push for cloud repatriation:
- Myth 1: You need to rebuild your data center team. Companies worry they’ll need to hire a team of hardware experts (and fire their AWS or Azure specialists). In reality, today’s data center partners (????) can deliver fully managed, turnkey infrastructure.
- Myth 2: It requires a huge capital outlay. Repatriation doesn’t have to mean spending millions on new hardware. Flexible billing models with managed services providers let companies treat infrastructure spend like OpEx, much as they do to use the public cloud.
- Myth 3: You lose automation. It’s worth repeating: The same tools used in public cloud environments now work in private data centers, delivering equivalent levels of automation without any vendor lock-in.
- Myth 4: It’s more expensive. Once you account for public cloud’s hidden costs (like data egress fees and over-provisioning), private data centers can reduce spend by as much as 80 percent.
- Myth 5: It takes a long time to provision. The modern data center provider has a wide array of managed services available immediately (e.g., object storage, virtual private servers, dedicated servers, etc.), and deployments can range from minutes to hours.
Old assumptions are still shaping today’s infrastructure decisions, leading teams to overlook just how far the modern data center has come. But the tools, services, and cost considerations aren’t the same as they were a decade ago. If you’re not already thinking about it, a hybrid approach can blend public and private cloud (ideally in a managed hosting environment) to give you the best of both worlds.
How to Know When It’s Time for a Switch
So when does it make sense to reconsider where you host your workloads? Cloud repatriation could make sense for your business if you need:
- Lower costs. Many organizations hit a tipping point where cloud costs far exceed expectations. A well-architected private data center can deliver major savings.
- Consistent performance. For latency-sensitive workloads (like AI inference or real-time analytics), private data centers offer greater predictability than a shared public cloud setup.
- Data sovereignty. Some industries can’t risk hosting data in shared public cloud environments. Repatriated workloads offer more control.
- Vendor stability. Right now, many organizations are grappling with what to do after Equinix EOLs its bare-metal offering in 2026. That’s just the latest example of a vendor’s changing priorities forcing its customers to scramble. One way to avoid similar issues in the future is working with a trusted managed services provider. You can use their team of experts to find a new solution and migrate smoothly without disrupting your business. (And if you happen to be looking for an alternative for your Metal workloads, we can help.)
If any of these apply, it might be time to consider cloud repatriation. And with the help of a managed services provider, you can migrate and manage workloads easily.
An experienced partner can provide the playbooks, guidance, and hands-on support to make the transition smoother. That includes everything from pre-migration assessments to downtime mitigation strategies. It also includes all the time-intensive infrastructure management (like patching, monitoring, and hardware upkeep) that keeps your team up at night.
With the right partner, you can free up your internal teams’ time and empower them to focus on revenue-building innovation. The impact: lower risk, lower costs, and the crack-free foundation you need to keep your business moving forward.
The Future Is Hybrid
The public cloud can feel comfortable for many companies. But comfortable doesn’t always mean efficient. Or performative. Or cost-effective.
When modern data centers offer so much value, leaders can’t afford to ignore hybrid infrastructure any longer. Whether you’re chasing better performance, seeking more control, or navigating economic uncertainty, cloud repatriation is worth a second look.
If you’re ready to embark on that journey, Summit can help. Let’s discuss how to build, manage, and optimize a hosting environment tailored to your business needs.